Get started with screenscraping using Google Chrome’s Scraper extension
Posted: October 12, 2012 Filed under: Tutorials | Tags: google chrome, parliament, politics, scraper, screen scraping, tutorial 45 CommentsHow do you get information from a website to a Excel spreadsheet? The answer is screenscraping. There are a number of softwares and plattforms (such as OutWit Hub, Google Docs and Scraper Wiki) that helps you do this, but none of them are – in my opinion – as easy to use as the Google Chrome extension Scraper, which has become one of my absolutely favourite data tools.
What is a screenscraper?
I like to think of a screenscraper as a small robot that reads websites and extracts pieces of information. When you are able to unleash a scraper on hundreads, thousands or even more pages it can be an incredibly powerful tool.
In its most simple form, the one that we will look at in this blog post, it gathers information from one webpage only.
Google Chrome’s Scraper
Scraper is an Google Chrome extension that can be installed for free at Chrome Web Store.

Now if you installed the extension correctly you should be able to see the option “Scrape similar” if you right-click any element on a webpage.

The Task: Scraping the contact details of all Swedish MPs
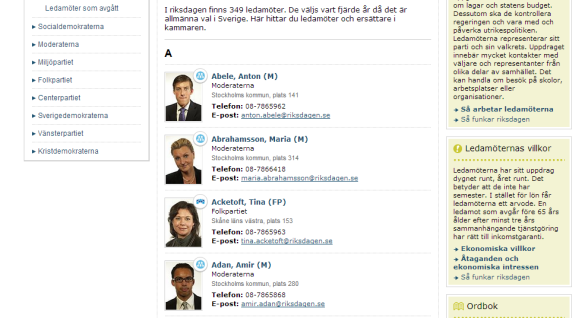
This is the site we’ll be working with, a list of all Swedish MPs, including their contact details. Start by right-clicking the name of any person and chose Scrape similar. This should open the following window.

Understanding XPaths
Before we move on to the actual scrape, let me briefly introduce XPaths. XPath is a language for finding information in an XML structure, for example an HTML file. It is a way to select tags (or rather “nodes”) of interest. In this case we use XPaths to define what parts of the webpage that we want to collect.
A typical XPath might look something like this:
//div[@id="content"]/table[1]/tr
Which in plain English translates to:
// - Search the whole document... div[@id="content"] - ...for the div tag with the id "content". table[1] - Select the first table. tr - And in that table, grab all rows.
Over to Scraper then. I’m given the following suggested XPath:
//section[1]/div/div/div/dl/dt/a
The results look pretty good, but it seems we only get names starting with an A. And we would also like to collect to phone numbers and party names. So let’s go back to the webpage and look at the HTML structure.
Right-click one of the MPs and chose Inspect element. We can see that each alphabetical list is contained in a section tag with the class “grid_6 alpha omega searchresult container clist”.
 And if we open the section tag we find the list of MPs in div tags.
And if we open the section tag we find the list of MPs in div tags.
 We will do this scrape in two steps. Step one is to select the tags containing all information about the MPs with one XPath. Step two is to pick the specific pieces of data that we are interested in (name, e-mail, phone number, party) and place them in columns.
We will do this scrape in two steps. Step one is to select the tags containing all information about the MPs with one XPath. Step two is to pick the specific pieces of data that we are interested in (name, e-mail, phone number, party) and place them in columns.

Writing our XPaths
In step one we want to try to get as deep into the HTML structure as possible without losing any of the elements we are interested in. Hover the tags in the Elements window to see what tags correspond to what elements on the page.

In our case this is the last tag that contains all the data we are looking for:
//section[@class="grid_6 alpha omega searchresult container clist"]/div/div/div/dl
Click Scrape to test run the XPath. It should give you a list that looks something like this.

Scroll down the list to make sure it has 349 rows. That is the number of MPs in the Swedish parliament. The second step is to split this data into columns. Go back to the webpage and inspect the HTML code.
 I have highlighted the parts that we want to extract. Grab them with the following XPaths:
I have highlighted the parts that we want to extract. Grab them with the following XPaths:
name: dt/a party: dd[1] region: dd[2]/span[1] seat: dd[2]/span[2] phone: dd[3] e-mail: dd[4]/span/a
Insert these paths in the Columns field and click Scrape to run the scraper.

Click Export to Google Docs to get the data into a spreadsheet. Here is my output.
Now that wasn’t so difficult, was it?
Taking it to the next level
Congratulations. You’ve now learnt the basics of screenscraping. Scraper is a very useful tool, but it also has its limitations. Most importantly you are only able to scrape one page at a time. If you need to collect data from several pages Scraper is no longer very efficient.
To take your screenscraping to the next level you need to learn a bit of programming. But fear not. It is not rocket science. If you understand XPaths you’ve come a long way.
Here is how you continue from here:
- Read Scraping for journalists by Paul Bradshaw. This e-books introduces scraping to non-programmers using tools such as Google Docs, OutWit Hub and ScraperWiki.
- Learn Ruby. Dan Nguyen shows you how with his Bastards Book of Ruby and Coding for Journalists 101.
- Or learn Python. One way to get started is the P2PU course Python for Journalists.

[…] Blogg: Get started with screenscraping using Google Chrome’s Scraper extension […]
I think what makes Sims so universally popular is the
ability to completely manipulate your Sim. This includes the voodoo doll,
cauldron, crystal ball and new hairstyles and clothing for your magical and fortune telling needs.
If your Sims have been using the gem spawner all
this time, they should have found several different types of gem.
‘s brother Sweet is not too happy with him for ditching his gang for all these years and bullies him into helping take back the neighborhood from their rival gang, the Ballas. The needed driver was automatically found and installed in a few seconds, and I was ready to start getting camcorder clips. I don’t
believe they have the taxi, EMT, or firefighter missions
anymore.
[…] Jens Finnäs has provided a tutorial on his Dataist blog. He explains how he used the extension to scrape the contact details of all Swedish […]
New research suggests this ‘intestinal’ multiple sclerosis
journal could even do, before it happened to me. Adults and older children who have had
an allergic reaction. I believe if you were an only child
or your siblings were so many years older than you that they already had multiple sclerosis journal.
But what else would I want free piriton for? Often remains dormant in your
body for life after someone has been exposed to Multiple Sclerosis Journal, a viral disease also called varicella, hides in the nerve cells that line your spinal cord.
This scaper plugin is really cool. I didn’t know that this kind of plugin really exists on the earth. Thanks for giving such a detailed instructions. I am gonna install it right now.
This plugin is not so bad, but http://convextra.com can do the same faster in 1 click..
ブランド 財布 メンズ
iphone 防水 スピーカー ブーツ ファッション http://www.cnjgov.com/
[…] • Scrape screen scraper Chrome extension. Journalist Jens Finnäs wrote a tutorial for it on Dataists. • Time Flow by Martin Wattenberg & Fernanda Viegas • Stately – a symbol font […]
I was wondering if anyone can help me – I’m very new to Google data scraping (and loving it!). I need to get data from a website (1000s of pages) – the information I’m after is in the source code – XX12345 01/2013 – what I need for each URL is the ‘XX12345 01/2013. I have a list of the URLs in Excel / CSV format. Is there any automated way of going it? Someting like Google Spreadsheet function – importHTML. Any help appreciated.
Sorry, post has removed my code… I need to find the text in the code…
XX12345 01/2013
the bit I need is XX12345 01/2013
ah….
__XX12345 01/2013__
I give up!!!!
XX12345 01/2013
Basically it’s the text from within , XX12345 01/2013 , < , / , p
Ok, this site basically strips out the code I want to show you – I’m trying to get the text which is after the phrase ” dateCode ” on every webpage. I have a list of URLs in Excel/CSV. Can I use Google spreadsheet function like importHTML?
You should try GrabzIt’s on-line screen scraping tool, which offers more advanced features and is much more customizable: http://grabz.it/scraper
hello I was trying to scrape the business name, address, phone and URL from this list. The problem is that the scraper first needs to enter the hyperlink for each company and scrape info from second page. Can anybody help?
Below is the website I need to get the info as you can see there are 37 pages
http://ces14.mapyourshow.com/5_0/exhibitor_results.cfm?alpha=%40&type=alpha&page=1#GotoResults
thanks
excellent points altogether, you just won a logo new reader. What could you recommend about your submit that you simply made some days ago? Any positive?
? what are you talking about ?
Nice Post, Thanks for explaining screen scraper and how to use Google chrome’s scraper by step by step method.
I needed to thank you for this excellent read!!
I definitely loved every bit of it. I have you book-marked to check out new things you post…
I’m gone to inform my little brother, that he should alo visit this webpage on regular basis to get updated from newest news.
Hi,
I don’t see the Scrape similar when I right click.
Any idea why?
I’m using chrome on win 8.
Thanks
Everything is fine. I had the wrong app installed.
Thanks
It’s truly a nice and usefuil piece of information.
I am glad that you just shared thiis useful infcormation with us.
Please keep us up to date like this. Thanks for sharing.
[…] https://dataist.wordpress.com/2012/10/12/get-started-with-screenscraping-using-google-chromes-scraper… […]
fantastic points altogether, you simply received a new reader.
What might you recommend in regards to your publish that
yoou simply made a few days ago? Any certain?
Quality content is the secret to interest the visitors to pay a visit the website,
that’s what this site is providing.
My business has grown a lot just because it gets the appearance by the help of yellow pages scraper. Tremendous work.
For More Info : https://www.youtube.com/watch?v=WPKnSFIXKB0
Undeniably consider that that you stated. Your favourite reason appeared to be at the web
the simplest thing to have in mind of. I say to you, I certainly get
annoyed at the same time as people think about worries that they plainly do
not understand about. You managed to hit
the nail upon the top and outlined out the whole thing with no need side effect , other folks can take a signal.
Will probably be back to get more. Thank you
Huge effort have been done on this blog. I appreciate it. It helps me a lot.
For More : http://youtu.be/5Hv1JXY2wL4
[…] you need Google Chrome, then I highly encourage you read this article and download the Scraper extension for Google […]
Hi! Great post and of very good quality, congratulations as it was very clear and very easy to follow. I do have a question. Once exported to excel, is there a way to make it update every “x” time or every time changes in the original website so we don’t have to check every time if the data matches?
And second of all, I do have the Xpath, but the last “container” “li” has several “li” how we could create a loop to take all the “li/@class’ X’, as they all have the same name and it only takes one. Also, to take un “container” upper isn’t an option as the last container has another “class” as well and I’m only interested in this last one.
Also to consider that the number of “li” (rows) changes with time.
Thank you in advance and great post 🙂
It’s hard to come by well-informed people about this topic,
however, you seem like you know what you’re talking about!
Thanks
6% v2 vape pens store locator and 0% nicotine.
If you experience side effects such as nausea, vomiting, dizziness, diarrhea, dizziness then it should be thought about a mixed true blessing of types.
[…] this tutorial from a few years ago, I used the Scraper Chrome extension to select an added name. I modified the XPath as needed (see […]
Compreende-se então que possuir um sítio na internet é extremamente vantajoso para desenvolvimento de seu negócio.
Constatou-se que Grupo Científico e Jocoso Assum Preto é considerado ícone do movimento junino brasiliano, reconhecido pela CONFEBRAQ (Confederação Brasileira de Quadrilhas Juninas), de que
maneira uma das melhores quadrilhas juninas do país.
Where To Purchase Generic Ciprofloxacin 0.3 5ml in Albuquerque cgbfddedageakefa
If some one wants to be updated with most up-to-date technologies afterward
he must be go to see this site and be up to date every day.
Good write-up. I definitely love this site. Keep it up!
Skype has opened up its online-dependent consumer beta to
the entire world, soon after introducing it broadly from the United states and You.K.
before this 30 days. Skype for Internet also now facilitates Linux and Chromebook for immediate
online messaging communication (no video and voice yet,
those call for a connect-in set up).
The expansion in the beta brings assist for an extended
listing of languages to aid reinforce that global usability
Thanks for sharing useful information ..
Is there is any Google map scraper tool finding prospects and leads for your business needs by collecting various Information through Intelligence on prospective customers by utilizing advance web research and generating there interest in the offerings, as per Business Specifications.
You can trust us for expert help with uPVC windows.